
What's New In Surgical AI: 9/10 Edition
We're Back, But A.I. Never Left


Welcome back! If you’re new to ctrl-alt-operate, we do the work of keeping up with AI, so you don’t have to. We’re grounded in our clinical-first context, so you can be a discerning consumer and developer. We’ll help you decide when you’re ready to bring A.I. into the clinic, hospital or O.R.
We had a little summer hiatus as we prepared for the academic year and settled into some newer roles. But, we are back. And while we’ve been gone, AI hasn’t stood still. Let’s walk you through the major milestones, including Med x AI announcements from the major players in the field.
Table of Contents
📰 The News: Big Tech makes Big Bets on Medical AI
🤿 Deep Dive: Human-AI Teams in Practice
📰 The News: A Recap of the Past Few Weeks
Over the past few weeks, all the major movers and shakers in the world of AI had major announcements. We’ll go through them, highlight the ones which might affect your clinical life, and talk you through what to expect in the future.
First, Teladoc has announced in integration of Nuance’s (owned by Microsoft) DAX AI clinical documentation system into its platform. Teledoc has over 50 million paying users, and their Solo platform is enterprise ready and allows health systems to engage with tele medicine without re-vamping their entire infrastructure. If there’s any system that can get AI into as many hands as possible, having Nuance, Microsoft and Teledoc on the same page is one of the best ways to do that.
Microsoft also announced a collaboration with the pathology AI company Paige, to make the world’s largest image based AI model for cancer. What exactly that looks like and how it assists in improving… anything … is left to be seen.
More recently, 3M (yes, that 3M) and Amazon Web Services (AWS) announced a partnership to bring AI documentation to 3M’s M*Modal speech-to-text software. Next to Dragon’s nuance, this is definitely the most high-profile speech to text system, now partnering with one of the big boys of tech. Let the games begin.
But perhaps all that glitters is not gold. A recent WSJ article looked into the AI note-writing startup DeepScribe and found that while most of its users believed their technology was using AI to write notes, much of the work was actually done by actual scribes.
Not to be left out, Apple is allegedly creating a chatGPT competitor, called Ajax. Combined with the new VisionOS, there is no reason Apple shouldn’t be in the AI cage match. Meta has recently announced Llama 2, which is an open-sourced, commercially licensable LLM. This is a major departure from the chatGPT and Bards of the world, which are completely closed models. This should hopefully allow builders of all shapes and sizes, including clinical teams, to start building robust infrastructure on top of these models. Maybe DeepScribe should take some notes…

Google had a few massive announcements related to medicine. They published their MedPaLM paper in Nature, with the inflammatory title: “Large Language Models Encode Clinical Knowledge”. Their model achieved 67% on the USMLE, and were judged to be helpful to laypeople 61% of the time. While these models are impressive there’s plenty left to wonder about how it can be rolled out in a useful manner. They also launched a multimodal model called MultiMedBench which can tackle a wide range of data:
MultiMedBench encompasses 14 diverse tasks such as medical question answering, mammography and dermatology image interpretation, radiology report generation and summarization, and genomic variant calling.
This is a natural extension of current capabilities of these models. Medicine is inherently multimodal, and so the ability to capture and encode a wide variety of data types, including images, is exactly what we expected would happen. Not to mention, everyone forgets OpenAI’s GPT-4 is actually multimodal as well. But to our knowledge, no one besides a few pre-selected partners have access to that system.

Hollywood and AI continue to be at odds, with writers and screen actors strikes painting a dystopian future for what A.I. could mean for work. The idea of using someone’s AI generated likeness is of course infinitely cheaper than actually paying for their time.
Question for the clinicians:
Assume there was an AI model that could answer initial triage questions with comparable outcomes to an urgent care. And assume patients were okay with seeing this A.I. clinic, and were actually going there. How would you as a clinician feel? Would there be an element of feeling like your territory was being taken from you?
For those who think there’s no clinical evidence of AI being helpful, those times may be changing. A new study in Lancet Digital Health showed that human-AI teams are noninferior to human-human teams in breast cancer detection in screening mammograms.
I think in some way we as clinicians feel that there is a uniquely human element to what we do, but these questions need to be addressed and dealt with head on. A.I. isn't replacing doctors anytime soon, but like with all technologies, its progress will likely disappoint both optimists and pessimists.
🤿 Deep Dive: Human + Medical AI teams Make it to Mainstream Journals
As discussed above, a recent publication in Lancet Digital Health by Dembrower et al., showed that human + AI teams performed with non inferiority to human-human radiologist teams in detecting breast cancer in mammography. The idea of human-AI teams are an important concept which will help determine the ability for AI systems to work alongside clinicians. It’s worth a deep dive.
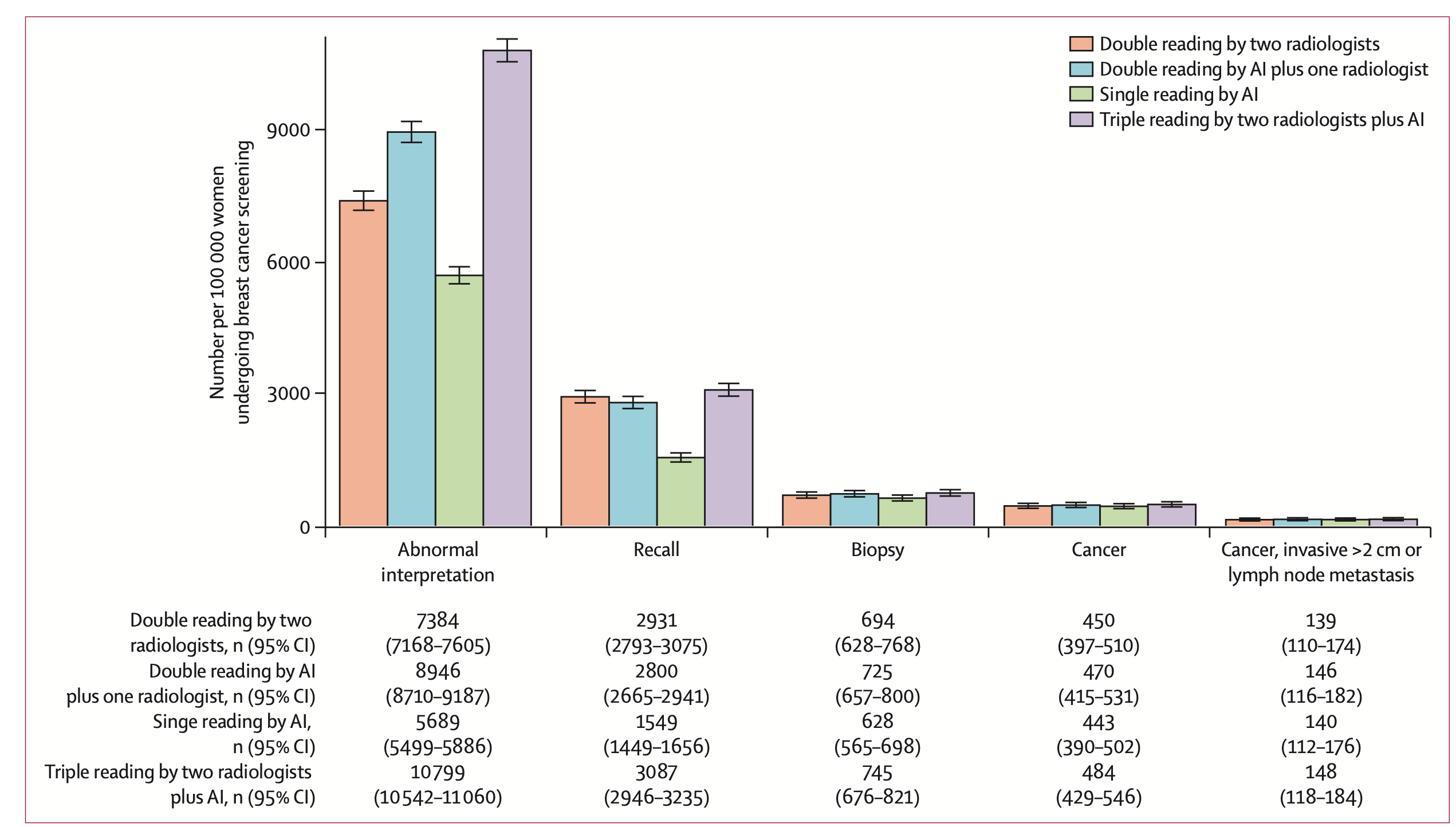
The study was conducted by a Swedish group, who enlisted an AI system to work in parallel to all radiologists at one hospital in Sweden looking at over 55,000 mammograms. The aim was to test the detection and false positive finding rate when the gold standard workflow (a read by two radiologists, blinded to the others response), versus a radiologist plus AI, versus two radiologists plus AI.
If any one of the three “readers” flagged a scan, it was sent to consensus by human radiologists, and then down the various diagnostic pathways until a final determination was made (via tissue, further imaging, etc).
The takeaways:
1 radiologist plus AI as a second reader performed identically to the gold standard. In fact, with AI and 1 radiologist, 11 more women had breast cancer identified than with 2 radiologists alone, a 4% increase in screen-detected, true cancers.
Single reading by AI was also non-inferior to double reading by two radiologists.
There were 19 cases where the AI was the only positive screening reader, prompting consensus conversation and subsequent diagnosis.
From the paper: “Double reading by one radiologist plus AI caused a 21% (868/4104) increase in the number of examinations with abnormal interpretation (following consensus by humans)”
Let’s unpack this.
The Radiologist + AI team had the exact same performance as a Radiologist + Radiologist team. This has massive implications. As the authors suggest:
In a screening population of 100000 women, replacing one radiologist with AI would save 100000 radiologist reads while increasing consensus discussions by 1562. Even if the consensus discussions would take five times longer than an independent read, the workload reduction would be considerable.
This would be a considerable time saver given the demands for precision diagnostics and increased imaging performed worldwide.
Another interesting point was that the AI + Rads group had a higher number of scans sent to consensus compared to Rads + Rads. This means that there may be a slight difference in how the AI is interpreting these images compared to the formal training a radiologist may have. Perhaps different systems with different training data may see different results.
This study did a great job of actually following through on the suggestions made by AI. All AI screened scans had to go to consensus. As a result, 19 women’s cancers were detected when they would have otherwise fallen through the cracks. The authors also test how AI would have done alone.
They come to the conclusion that it actually performs as well as the gold standard (two radiologists). However, they make a point which I think gets to the core of why human+AI teams are the way forward, versus AI alone.
[If AI were screening mammograms alone]… “ it would mean that a large proportion of mammograms would never be assessed by a board-certified physician”
This sentiment is unsettling amongst physicians, and likely amongst the public as well. It creates important questions around reliability, public perception, and in the US, liability.
The Shortcomings
While the study was quite robustly designed, it was not randomized. The true litmus test would be to randomize scans into either Rads+AI, Rads+Rads, or Rads+Rads+AI cohorts, and determine the outcome. Knowing it Rads+AI is non-inferior, it is reasonable to then go forward with a larger, prospective, randomized study.
One important consideration is the significant testing which went into choosing an AI system in this paper. It is worth questioning what criteria you would choose when deciding what AI system you would want to work with. We’ll leave it up to you:
Best of Twitter:
Maybe one day Elon’s feud with substack will be over. What should we replace this with? Let us know via email.
Feeling inspired? Drop us a line and let us know what you liked.
Like all surgeons, we are always looking to get better. Send us your M&M style roastings or favorable Press-Gainey ratings by email at ctrl.alt.operate@gmail.com