
What's New in Surgical AI 2/19/23
Vol 13. When Humans Attack


Welcome back! Here at Ctrl-Alt-Operate, we dissect through the noise and isolate the signals driving A.I. innovations in medicine and surgery to keep you one step ahead of the headlines.
As always, we’ll go through what happened this week (if it matters to the surgical community) and award one coveted trophy emoji (🏆). This week’s tweets bring you an AI medical search tool to keep your clinical performance in tip top shape, manuscripts of the week from ArXiv, a new dataset for our computer vision colleagues out there looking for new tasks to train their models against, and a few other choice picks from across the twitter-verse. And we are off!
Table of Contents
📰 The News: AI underperforms and new avenues for AI research
🤿 Deep Dive: What makes A.I. Models Break (Pt 1): Adversarial Attacks
🎥 A Future Where You Don’t Spend Hours Editing Surgical Video?
🏆 Content of the Week
The News
Side Bar: This weekend, we attended a subspecialty neurosurgery conference, and even in this relatively niche selection of academic surgeons, there was an overwhelming support of A.I. applications to make surgery better. We are excited to see this community continue to grow and hope we can filter the signal from the noise when it comes to the daily changes.
Over the last few days, celebrated AI systems such as chatGPT and Bing (aka “Sydney”) exhibited unexpected and undesirable performance when exposed to certain inputs from users. With a few keystrokes, users could turn even the most powerful chatbots into satanic, manipulative and racist hate spewers. The chatbots would claim “I want to be alive” (giving it the front page of the NYT…), go on explicative filled rants about its creators (this one is quite funny) and even admit to wanting to steal nuclear launch codes and enable armageddon!
Meanwhile, British legal giant A&O publicly announced that they are integrating GPT-based technology into their daily work, so these hate-bots might be writing your legal contracts soon. In parallel, researchers are developing ethical standards for interacting with AI.
This was a good week if you do A.I. research! The New England Journal of Medicine announced an AI exclusive journal. Can’t wait to get our papers rejected from them! Similarly, Cureus, the Stanford spin-off journal is calling for submissions for chatGPT assisted case reports. How do we feel about this? Sound off in the comments.

Long Dependencies Solved? It Depends… Transformers that are capable of modeling long sequences (time-dependencies) are of great interest to me. I don’t have many opinions about the practicality and implementation about this approach from a group at Yale, but it is cool to see progress in this area which has implications for inference from surgical video data.
Bigger Isn’t Better: Emily Alsentzer of BioClinRoBERTa fame has a new preprint that compares models ranging from 200M - 175B parameters on standard NLP tasks in clinical medicine. Pretrained but smaller clinical models such as BioClin outperformed larger models such as GPT3 on most all tasks, even using few-shot (in-context) learning.
We love big data sources here at Ctl-Alt-Operate. So shoutout to Dr. Pirotte for a public db of >500 airway videos.
🤖😔 Deep Dive: Testing The Limits of A.I. Models
To double-click on the news from this week, chatbots are claiming to fall in love, desiring to be human, or exploring their murderous dark sides. This is what can happen when humans try to make AI systems fail, a phenomenon called “adversarial attacks”.
Those are also a sort of adversarial attack, where the text prompts entered by the user generate a significant deviation in model behavior from the expected/desired output. Surely, Microsoft doesn’t “want” a chatbot that asks its users to divorce their spouse and cops to desire the nuclear launch codes ? Right … right?
Why does this matter to a surgeon?
In short: because in your career, these models will be integrated into your clinical practice and into your ORs. Sometimes they may just be “software updates”. Just as knowing the limitations of an approach is necessary for the OR, knowing where these models are vulnerable is imperative for any AI-forward surgeon.
Let's back this up a little and introduce 2 concepts which are key for your understanding of A.I. applications: training data and learning.
In 2016, DeepMind’s AlphaGo beat the greatest human Go player, Lee Sedol, in 4 our of 5 matches, ushering a new era of “AI capabilities.” Go is a particularly strategic and difficult game for AI to learn, with many more possible moves than chess. After AlphaGo, Go was “solved” and it was well known that no human could be the AI. Until now, when a human finally beat the AI by:
The tactics used by Pelrine involved slowly stringing together a large “loop” of stones to encircle one of his opponent’s own groups, while distracting the AI with moves in other corners of the board. The Go-playing bot did not notice its vulnerability, even when the encirclement was nearly complete, Pelrine said.
source: FT
The key point is that while the original Go-AI’s were trained on prior human games, and even trained by other AIs playing against each other, they didn’t cover all of the possible situations that could occur. This is the concept of training - that a corpus of data is used to build schemas of performance by the model.
In the case of AlphaGo, the training was robust enough that it did phenomenally for years, and continually kicked humans’ butts. However, apparently a ring-around-the-rosie method was so out of left field, that the model didn’t know how to handle it.
Out-of-sample generalization is a core challenge for AI, particularly in medicine. Can a predictive model recognize when it is modeling a patient that deviates from its training data in important ways? Can we encode simple heuristic and representations into the model to ensure that it doesn’t perform worse than an amateur human, or that it at least knows when to call for help? Right now we simply don’t know, but we certainly hope to be able to do these things.
So it seems the problem is deeper, and while others have blamed the specific architecture, rushed testing environment, and AI-model arms race for releasing a psychopathic stalkers AI unto the world, I wonder if the problem isn’t simpler.
Could it be that even the biggest AI orgs don’t have a way to algorithmically identify inputs that are outside the training set of the model, and can’t efficiently, algorithmically identify outputs that are problematic? We definitely need those guardrails before we deploy these concepts in patient decisionmaking in medicine.
This does bring us to another point: who decides what content is problematic? Is it acceptable to have a chatbot that makes fun of Republicans, but not Democrats? That allows NYT style writing but not NY Post article generation?
This is a good opportunity to bring up the concept of learning. You hear learning all the time - supervised learning, unsupervised learning, the new “hot term” is RLHF (reinforced learning with human feedback). These all correspond with simply: how much information does the model get when trained.
In the case of chatGPT, a big reason the responses are so strong is because each time you respond to the model, it reinforces (or extinguishes) behavior with your feedback - aka reinforced learning with human feedback, or RLHF. Nice job, now you can impress your tech friends at your next dinner party.
Does it matter if the model expresses those behaviors as a result of training and reinforcement learning, or whether the interface explicitly guides the model output through prompt instruction?
Bringing it back to medicine, if a model is trained by BigDeviceCorp do we know its weights and biases? If it provides recommendations, do those have implicit or explicit narratives by way of the training data and learning paradigms? These terms matter and will help you navigate these waters in the coming years.
🎥 Sneak Preview for Surgical Video Editing: capsule.video
Lets imagine a better way to create educational surgical video. Instead of spending hours downloading, reformatting, transcribing, and creating captions for slides, what if you could upload your video to a website, automatically generate templated slides for your review with a transcript attached? Well, it’s not quite optimized for our applications, but capsule.video is one exciting team to watch in the PR & marketing space. We can encourage these efforts in our spaces as well.
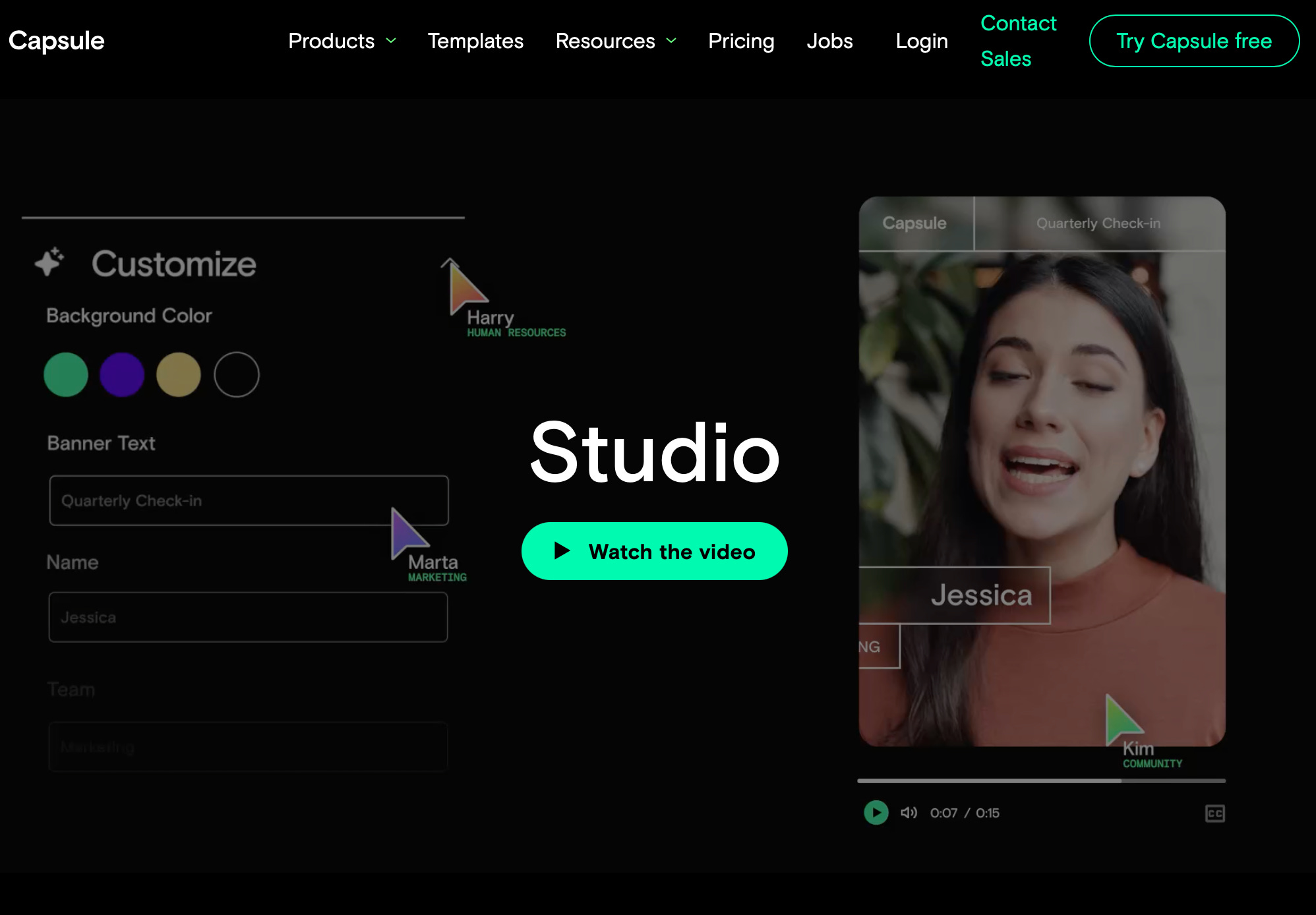
But this had us thinking…
Tweet of the week
🏆Tweet of the Week: Just because we promised we would stop fanboying for chatGPT, doesn’t mean that I’ll ever stop loving new GPT-based applets. This clever implementation by @samarthrawal uses embeddings across the NLM stat pearls database serves up high quality recommendations and content from nationally accredited and peer-reviewed clinical fact sheets. Definitely a step in the right direction. Kudos!

When we started Ctrl-Alt-Operate, our goal was to share all of the work we were doing behind the scences to stay up to date with the AI-pocalypse. This week, we blew past 100 subscribers 🚀🚀🚀. Thanks for being a part of the community. Please like and share below if you find value!
Feeling inspired? Drop us a line and let us know what you liked.
Like all surgeons, we are always looking to get better. Send us your M&M style roastings or favorable Press-Gainey ratings by email at ctrl.alt.operate@gmail.com