
What's New in Surgical AI: 01/29/23
Vol 10: ChatGPT Passes the USMLE and others.


Welcome back to another week of excitement from the Cambrian explosion of large language models. ChatGPT has driven the hype cycle for “passing the USMLE”, “being ready to replace doctors” and similarly salacious claims. We’ll dive deeper into chatGPT as a knowledge assistant on standardized tests, then discuss how practicing physicians and computer scientists can integrate LLM into clinical workflows and patient care. We might even help you come up with a solution for those overflowing patient portal message in-baskets. And there’s a gem of an xkcd comic buried in this week’s letter.
Here at Ctrl-Alt-Operate, we cut through the noise (even if it comes from everyone’s favorite replitter-in-chief @amasad) and amplify the signal for clinicians, scientists and engineers working at the intersection of surgery, medicine and AI. If you want to make your friends smarter or keep the goodness flowing, here are the requisite buttons:
Table of Contents
🤖 ChatGPT vs the USMLE
🌈 The future of AI assistants for MD’s
🎺 Twitter News
First, we should foreground our discussion in our priors and framework for evaluating LLMs in the clinical domain.
Since we are both technologists and clinicians, our long term optimism about AI is tempered by our experience living through two decades of “hype waves” crashing against the obstacles of clinical reality. We are necessarily forward thinking, but remain grounded in the foundations of our present constraints. In evaluating a new technology that proposes to interact with today’s medical clinicians, we consider several factors: What regulatory and organizational constraints shape the terrain today? What are the knowledge, beliefs and attitudes of clinicians that influence acceptability and adoption? What are the constraints on delivery systems, UI/UX and deployment environments? What are the consequences of failure, and how are humans likely to detect and respond to failure modes? How does a new technology interact (strength, disrupt) with existing incentive structures (financial, practical)?
But, these are our takes. So let us ask you: is this what we accomplish?
ChatGPT vs the USMLE
Kung et al.1 looked at how chatGPT performed on the USMLE. They used the same chatGPT that can write poems and recipes, without additional fine tuning, prompt engineering or few-shot approaches. The team took approx 300 publicly-available USMLE questions (split approximately evenly between step 1, 2 and 3) from the June 2022 sample exam, and asked them to chatGPT.
The study found that when ChatGPT attempted to answer the test questions, its accuracy was 62.3% for Step 1, 51.9% for Step 2CK, and 64.6% for Step 3. These numbers are actually quite impressive when compared to the USMLE pass threshold, which is around 60%, and exceed domain specific models with fewer parameters (PubMedGPT, 2.7B parameters on GPT-2, vs. ~175B params for Chat). If you want to take a deeper dive into the passing threshold for USMLE, check out the irascible Bryan Carmody’s take here.
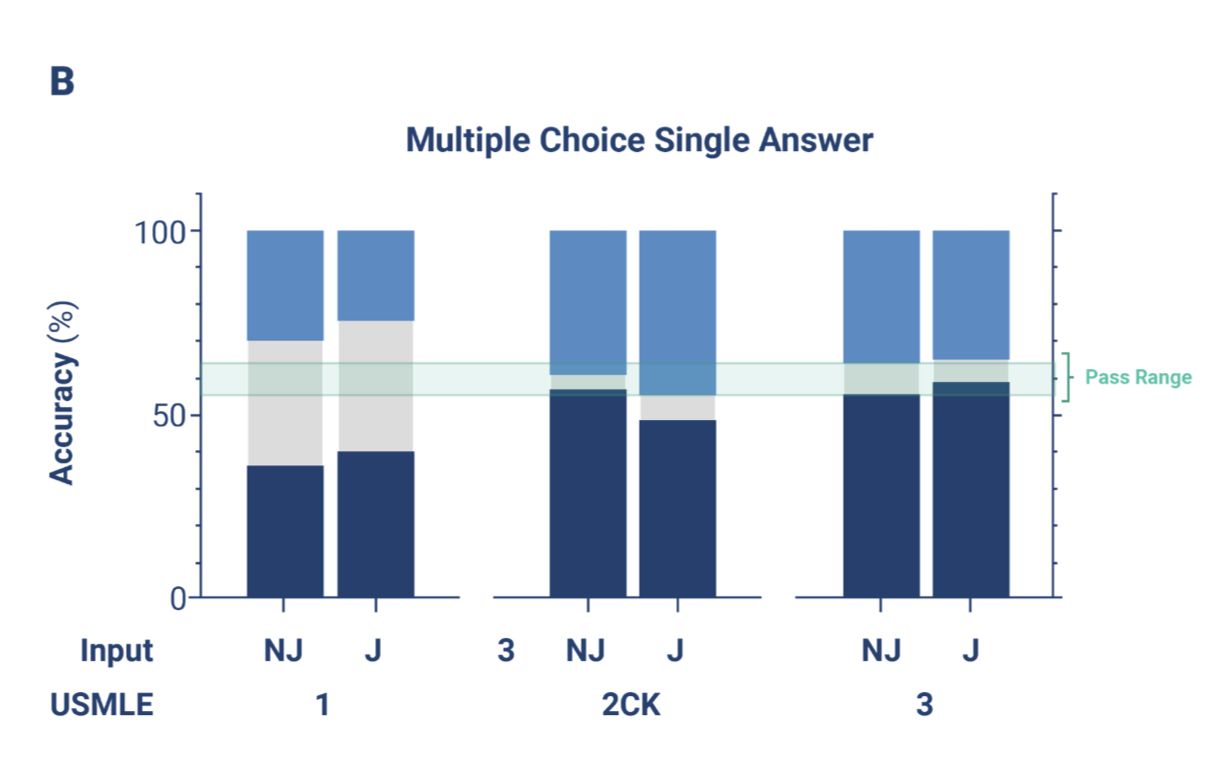
Kudos to this research team - they answered a question every anxious second year medical student has been asking for years: “can a robot just take this exam for me?”
A few important caveats:
The grey portion of the bar graph represents “indeterminate” responses - this is where chatGPT either did not provide an answer, said it didn’t have enough information, etc. This may be due to limitations imposed on the ChatGPT interface, difficult question types, or other factors, and made up about 1/3 of the Step 1 questions. In truth, for now, these should be considered as “incorrect”.
All images were excluded from this study. This is reasonable as ChatGPT is a large-language-model, not a model trained on images. Two strategies could be used to overcome this. First, simply detecting the image type (pathology slide showing cells, radiology image showing head CT) might be “good enough” in some circumstances. Second, medical-domain performant image-to-text systems could be applied since Step 1 doesn’t show degraded or indeterminate images.
The authors did not use known methods for improving the performance of GPTs, meaning that the study may represent a lower bound that could be exceeded with minimal change in the underlying model. The researchers provided no prompting or training to the AI, minimized grounding bias by expunging the AI session prior to inputting each question variant, and avoided chain-of-thought biasing by requesting forced justification only as the final input.
Takeaway Insight: The most important value of chatGPT in its current incarnation is its ability to augment, not replace human insight. In qualitative assessment of chatGPT’s performance, the study authors found that nearly all responses (89%) generated meaningful insight which could be used to:
educate learners directly (“help me learn the coagulation cascade”)
create education material
create test questions and clinical vignettes (competition to UWorld?)
According to our framework, this study demonstrates underwhelming incremental improvement towards clinical use of chatGPT as a freestanding medical question-answering application. Compared to its other language abilities, improving score on USMLE questions remains far below the threshold at which it might even be propose to stand alone in a clinical knowledge task.
Twitter trolls were quick to jump aboard the “AI will replace doctors” train.
Like most internet discourse, this feels hyperbolic, oversimplified, and ignorant of the past 20 years of medical knowledge systems (Watson, anyone?). As anyone who has taken the USMLE can attest - passage is a necessary but not sufficient criteria for being a physician. The exams were developed to certify humans as competent to proceed in medical training according to normative performance data and reflective of a common underlying medical school curriculum.
The biggest positive from the proliferation of LLM into the clinical knowledge domain is that it may trigger a much-needed rethink of how we determine competency in humans. Does it really make sense to keep asking the same questions every year when AI-assisted knowledge retrieval is getting easier and easier? Should we keep training doctors to memorize material that they will rarely, if ever, need to retrieve in their daily patient care? Should we consider moving to a GPT+Human medical licensing exam, where we measure performance that is more reflective of actual clinical practice? But before we get too far ahead of ourselves…
What does this mean to you?
What this means for you today:
ChatGPT is powerful, but limited. We have seen examples of people using it for prior authorizations, to summarize patient encounters, etc. Find your niche and see what works for you.
You will certainly soon get patients providing you info they got from ChatGPT. The new ‘WebMD’. Be armed with knowledge. Knowing where the pitfalls and pearls are, are important. Do I trust it to cite the right guidelines for diabetes management? Not really. Do I trust it to create diabetes-friendly recipes with expert review? Absolutely.
Integrating LLM into human-in-the-loop systems is useful, but unpredictable. As clinicians increasingly become mesmerized by the beautiful poetry of chatGPT, we must remain watchful for its small slips and unexpected failure modes. The ability of an unconstrained and unreviewed LLM to hallucinate plausible sounding text can have dire consequences in medicine. We simply don’t know why chatGPT writes what it does, is it weighting Andrew Wakefield or Tony Fauci more heavily?
GPT makes up all references to the medical literature. Dan can’t get enough of this particular soapbox, despite knowing better than to tweet every time someone is wrong on the internet, and this is his third or fourth “reference rage out” in this newsletter. In fact, he hates it so much, he might even come up with a solution…


What this might mean in the future:
Let’s think optimistically for a second. How could AI help us make fewer errors, communicate to patients better, get home a little earlier, and be better at our jobs? Here are some thoughts:
How much time is wasted performing clerical tasks which could be automated using an intelligent system with tight oversight? Imagine this: a patient wants to reschedule. An AI assistant triages the acuity of the visit, what the patient prefers, and automatically pings you with the information. You respond with your preference, and the chatbot communicates with the patient.
Inbox zero. Medical portal messages are the bane of every clinician and one of the single largest contributors to burnout in modern medicine (a truly impressive achievement). The asymmetry of the speed at which a patient can ask a question and the time required to give a medically correct and complete answer has led some institutions to start billing patients for the ability to write messages to their MD.
A partner to interact with. One of the best parts of medicine is collaboration. But your colleagues can’t always be there. But their AI could be! If you could just chat with their AI, you could know how your colleague might have managed this complex patient, or similar situations in the past. Or it could even search your prior history to suggest common responses that you’ve made in the past to similar inquiries
Lower bar for physician-led innovation. All of these solutions may be easier to build than ever. With the advent of no-code and low-code deployment platforms, we might even see a proliferation of useful apps built by and for physicians (wink wink) that solve actual daily problems.
Twitter Roundup:

Cool. OpenAI x Azure x HIPAA (holy trinity?). Or, is this the beginning of the rise of the hegemons?

We need more people like Dr. Oates. Kudos and strong work!
Admittedly, calling something from AI21 “exciting” is perhaps an understatement, but it’s important to highlight the exciting ways in which prior corpora of language can be used to significantly improve black-box model performance without having to modify the underlying model.
Feeling inspired? Drop us a line and let us know what you liked.
Like all surgeons, we are always looking to get better. Send us your M&M style roastings or favorable Press-Gainey ratings by email at ctrl.alt.operate@gmail.com
https://www.medrxiv.org/content/10.1101/2022.12.19.22283643v2.full.pdf