
What's New in Surgical AI: 01/19/23
Vol 9: Keep the chatGPT flowing, with a dash of AI


Welcome back to Ctrl-Alt-Operate, where we connect clinicians, students, and scientists at the forefront of AI and surgery.
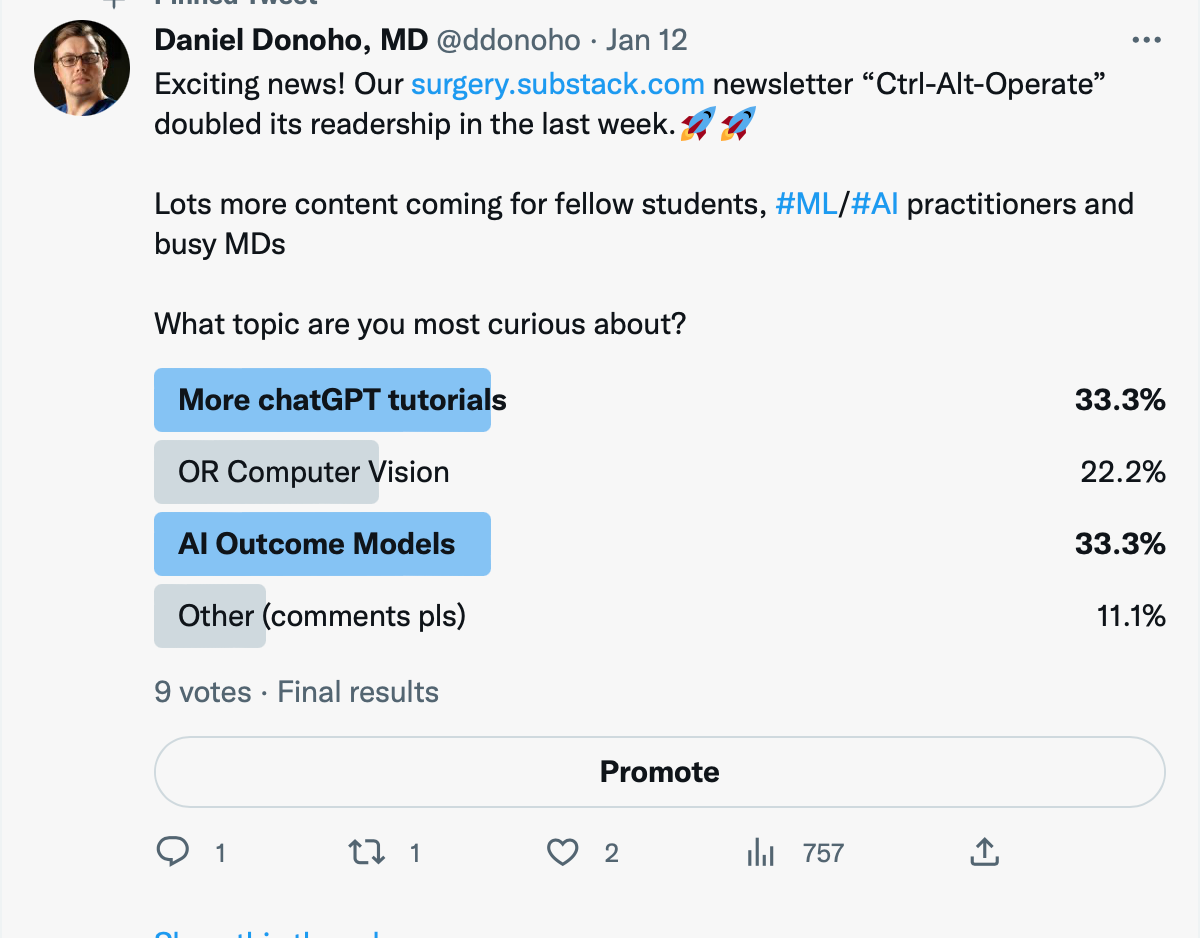
Before we continue, a quick poll of our readership:
Thanks for that! It helps us curate content better for you.
This week, we delve into the latest developments in chatGPT (which includes a potential $10 billion investment in OpenAI by MSFT 0.00%↑ ). We also share some everyday uses for clinicians interested in chatGPT, and highlight a new AI outcome prediction for surgical patients.
ML/AI scientists, take note, there may be opportunities to contribute to the field. Students, pay attention for potential USMLE/MCAT points.
If you're not a subscriber yet, join us by clicking the subscribe button below.
Table of Contents
We are a substack for the people! Here is the twitter poll driving us this week:
🦾👩🌾 Deeper into the ChatGPT Jungle
Since we last spoke, chatGPT has gone from the front pages of the New York Times to Eric Topol’s substack (“When MD is a Machine Doctor”, a worthy read here). It has conquered the US medical licensing exam, summarized radiology reports, and forced academia to rethink homework . ChatGPT was even included as an author in a peer-reviewed paper.
Challengers such as Claude, a closed beta from Anthropic AI, are breathing down chatGPT’s neck.
Our last issue (below) described a variety of use cases for chatGPT, ranging from personal documentation (very ready) to literature searchers (not ready). Click below for a refresher on what we covered:

This week, we're showing examples of how chatGPT can be useful in everyday life.
What if chatGPT could answer questions based on your personal notes?
The most obvious and immediate use of chatGPT is against your own library of data. Imagine you’re studying for an exam and typing in your notes into a google doc, but then still have to sit there and manually make flashcards from the text you’ve already entered. Boring!
Enter Jesse Zhang’s GPTPapers LLM demo

Here’s the skinny: This tool allows you to ask questions, summaries, or perform other chat-GPT-like tasks on data you give it (in this case, Arxiv Papers). Soon to come: Google Docs integration. Who needs a study partner to ask you questions when you have large language models?
What if you could look up data from your favorite clinical resource in seconds?

This exciting demo shows how models with access to guidelines (in this case, UK NICE guidelines) can effectively pull information from that datasource and answer specific questions. Importantly, the creators claim it reduces the (very dangerous) propensity for chatGPT to hallucinate. aka: provide very confident, very incorrect, answers.
It’s not hard to see how these models could use data from textbooks, society guidelines, or other corpus of literature to provide information within seconds. Perfect for a night on call, or seeing a patient with “zebra” pathology.
You might be asking…
How are these different than chatGPT? These models rely on embeddings.
Embeddings are a way for computer models to understand the meaning of words and phrases. They work by giving each word or phrase a unique code, like a map that shows how similar or different they are from each other. This helps GPTs understand the context of a word.
For example, “after the bat hit the ball” and “the bat in the cave” both contain the word bat. The embedding values for the words before and after bat allow a model to determine the context - in this case: America’s pastime, or a small nocturnal creature with wings.
These values also help models find the most relevant documents for a search by comparing the codes of the search words and the documents. In this way, developers can use a combo model of embeddings + GPTs to index, query, return and summarize the most relevant search results.
Other exciting tools in this area include:
GPTindex (twitter:gpt_index), which could be used to build exactly the app you would want to search your own notes and do QA.
allsearch.ai which searches across 1000s of books including first aid 2012 for the USMLE step 1.
langchain, inspired by prior work from google, that allows chaining requests to LLM
If you’re a pandas user, check out sketch, which allows code generation from natural language for dataframes.
Squidgies.app which currently supports language learning, but we can dream that someday it might support medical knowledge across a known corpus
🏆 Paper of the Week: AI Outcome Prediction
Amidst the extreme noise of AI x Medicine, friend-of-the-substack and rising superstar Dr. Tyler Loftus has led a multiyear NIH-funded effort to disentangle a tricky problem in health care: matching patient acuity (severity of illness) to intensity of care.

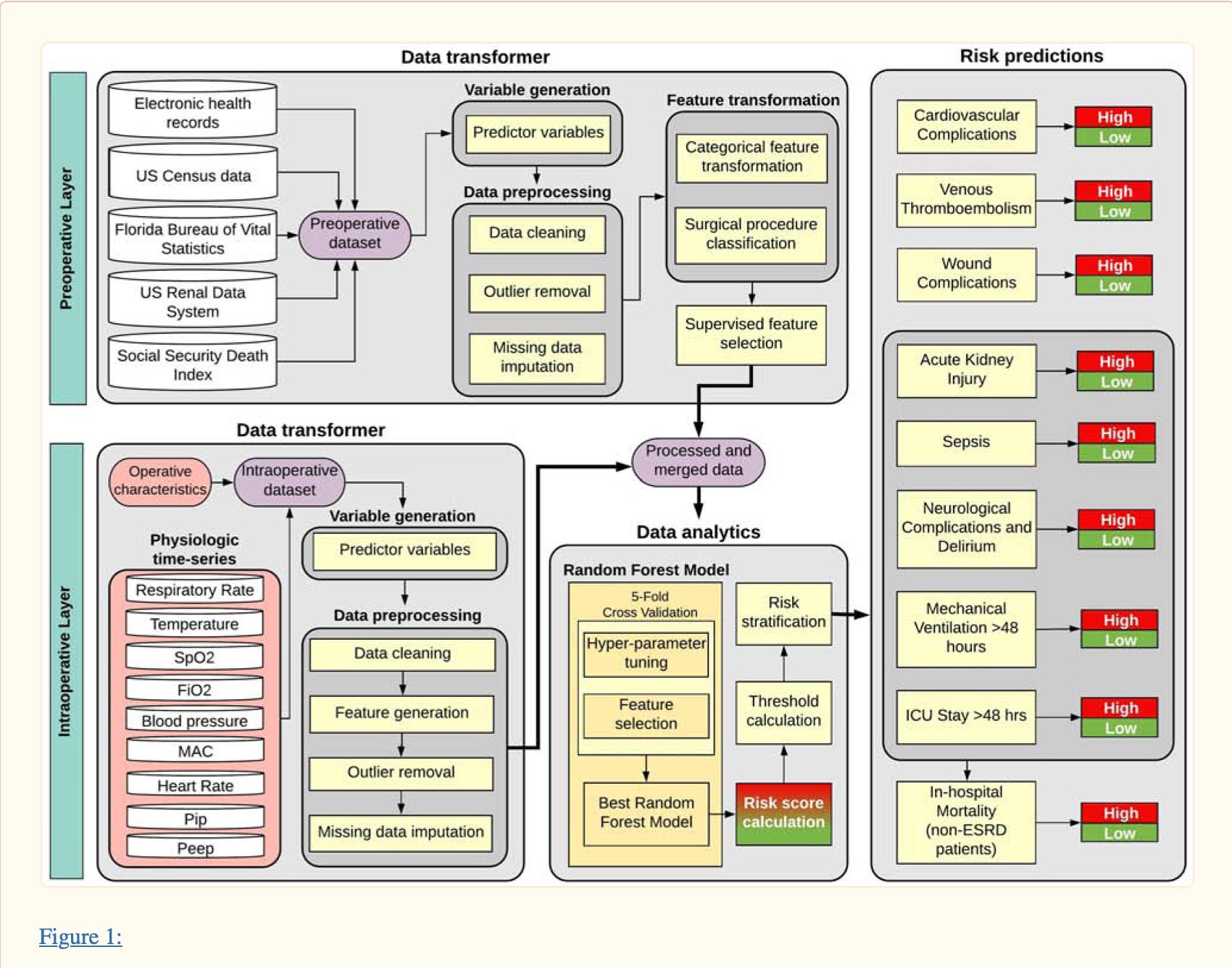
The essence of their idea is simple and well understood in medicine. The acuity (severity of illness) of a patient should be matched with the intensity of care they receive. In the real world, our allocation of medical resources is imperfect. In our current climate, ICU beds are scarce and surgeons typically have to decide weeks in advance whether a given patient will need the ICU, or face the prospects of not having a bed available.
I recently had a patient wait for two days in the recovery room without an ICU bed, despite knowing they needed one. This highlights the current imperfect allocation of resources and the consequences of getting it wrong. In prior work, Loftus et al. found that 5% of patients who don't "need" the ICU but are sent there anyhow have little benefit and 50% increased healthcare cost. On the other hand, the 12% of post-surgical admissions to a general floor ward who "need" the ICU but don't go, have more than double the odds of death.
Loftus et al. propose a solution: an explainable ML-based model (details forthcoming) that allows clinicians to understand why a patient is being classified as “high” (ICU) or “low” (ward bed) acuity. Their prior work described a random-forest based model that incorporates both large publicly available and electronic health records outcomes datasets and local institutional data from the electronic health record obtained during surgery.
Stay tuned for more from the University of Florida group. Exciting work.
That’s all for this week. The AI landscape is ever changing, and you can rely on us to keep you up to speed on how these changes might impact medicine, your practice, and your patients.
Feeling inspired? Drop us a line and let us know what you liked.
Like all surgeons, we are always looking to get better. Send us your M&M style roastings or favorable Press-Gainey ratings by email at ctrl.alt.operate@gmail.com
The work by Dr. Loftus appears incredible (and equally interesting)! Explainable AI applications in medicine are what physicians want due to understandable insights generated by these complex models.