
What's New In Surgical A.I.: Memorial Day Edition
Neuroscience is back in the news, and we explore the phenomenon of doomers in AI


Welcome back! If you’re new to ctrl-alt-operate, we do the work of keeping up with AI, so you don’t have to. This week, we explain how brain computer interfaces are helping patients walk, discuss a new library that allows semantic search over unlabelled images (pretty cool, for the nerds), and remind everyone that most people still haven’t heard of GPT’s. On the other hand, a vocal minority of technologists have become doomers, arguing that the rise of AI will lead to apocalyptic outcomes. We will take a deep dive into the doomer phenomenon and bring it back to medicine, where it has never been thoroughly discussed. As always, we are grounded in our clinical-first context, so you can be a discerning consumer and developer. We’ll help you decide when you’re ready to bring A.I. into the clinic, hospital or O.R.
Table of Contents
📰 The News: Neuroscience is cool again!
🤿 Deep Dive: Doomers, Medical Education, and
🪦 Best of Twitter:
📰The News: Neuroscience Back on the Cool Throne
Congrats to everyone who had NVDA 0.00%↑ in their portfolio this week, shoutout to you- it is clear that despite a hazy macroeconomic picture, the A.I. train and business need for computational power remains undeterred. Also highly recommend this podcast which dives into NVDIA’s CEO, Jensen Huang. My favorite part of the podcast: his parents immigrated to the US and meant to send him to boarding school, but instead sent him to a remedial school where he tutored his ex-juvy roommate in math in exchange for learning how to fix up Harley Davidsons. Awesome stuff.
Onto the news.
The world of AI, Neuroscience and functional neurosurgery went mainstream this week. A team out of Switzerland developed a brain-spine bridge to help a man walk after a motorcycle accident left him paralyzed in 2011. The subtleties of the technology are the interesting parts here, and the full paper is here. Brain-computer-interfaces have exploded in popularity and funding- where electrodes implanted on cortical surfaces can record, transmit and even interpret electrical signals. Simultaneously, in the spinal cord injury world, epidural electrodes that send signals to lower motor neurons to activate muscles (via a backpack-like mechanism), have been able to allow spinal cord injury patients to take steps. However, a machine deciding to make your muscles move was a reasonably unnatural experience.

The Swiss team bridged these two technologies, and decoded BCI-based movement patterns and paired them with LMN electrical impulses to simulate a much more “natural” walking feeling. This is a step (no pun intended) towards definitive care for spinal cord injury patients who are otherwise generally young and healthy.
In more neuroscience news, Elon Musk announced his BCI company Neuralink has received FDA approval to start clinical trials. For what? For whom? With what endpoints? No details disclosed.
For some more research-y news, a team out of Stanfords AI Lab has launched meerkat, which enables foundation models (think chatGPT, large scale vision models, generative image models like DALL-E) to be applied to unstructured data.
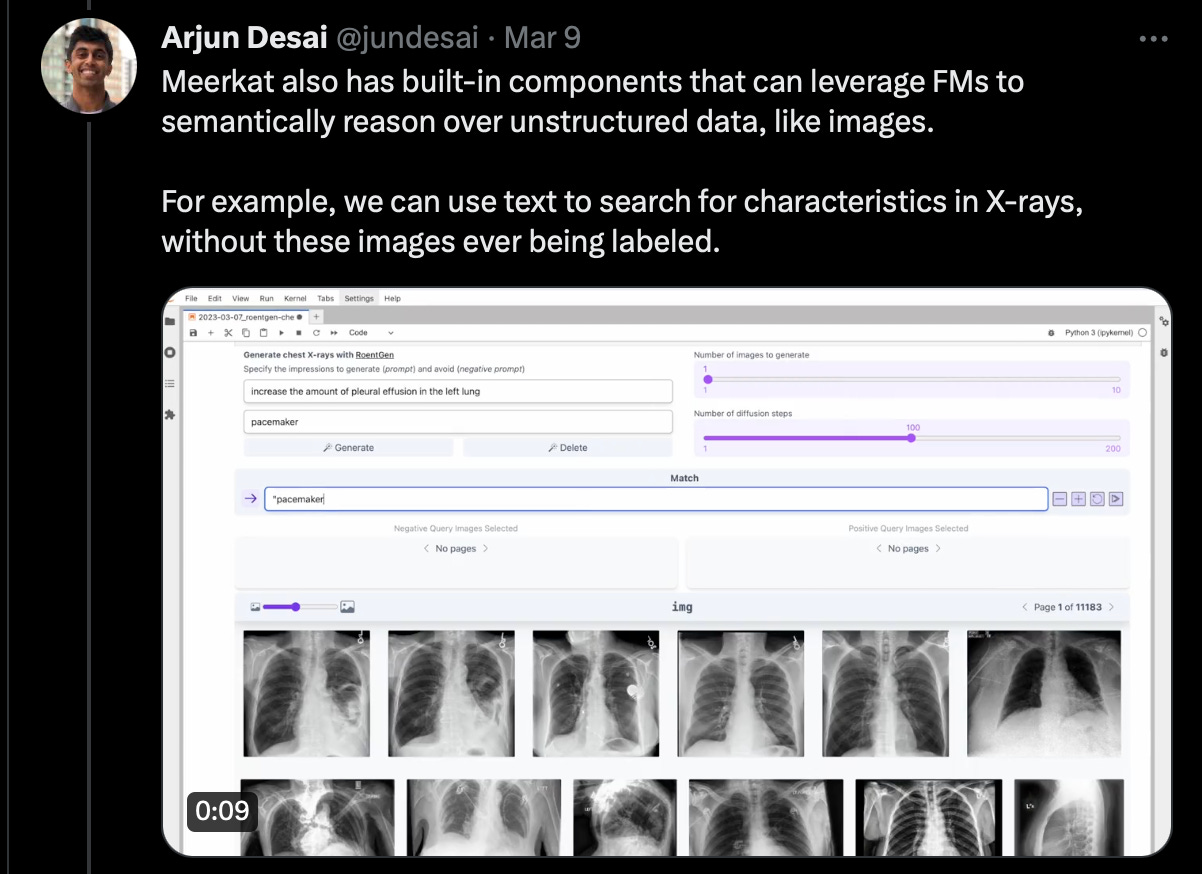
Impressively, the team leverages foundation models to reason over images, using text to search for characteristics without these images ever being labeled. Here, they look for pacemakers in CXRs. Conceptually, this makes sense. If a model can reason through what a pacemaker looks like, where it is inserted, etc. it can reasonably find CXRs with an artifact on the L side of the patient (plus any small number of images with pacemaker labels).
This appears to be a powerful tool for data scientists, particularly in medicine, where so much of our data is 1) unstructured and 2) multimodal.
One of the faculty building meerkat, James Zou, was on the Vital Signs podcast, which you can listen to here.
In other news…
The Pew Research Center found that while a majority of Americans have heard of chatGPT, few have tried it themselves. This is a good reminder for those in the A.I. echo chamber, of which we are squarely guilty of being a part of, that this is still brand new technology. Specifically, only 14% of Americans have actually tried ChatGPT.
I guess now is a good time to bring back this classic from 1995:
🤿Deep Dive: Doomers, a pre-mortem for AI in Medicine.
As chatGPT swept the front pages of our popular press, a minority of technologists publicly argued that technological advances expressed in AI systems were extremely dangerous. These AI doomers, issued a public call to pause all AI research which attracted signatories such as tech leaders (Musk, Wozniak), former presidential candidate Andrew Yang, intellectuals (Yehoshua Bengio, Gary Marcus, Eliezer Yudkowsky), and 31000+ other compatriots. Yudkowsky argues that design flaws and evolution over time could lead to unforeseen risks, and even the end of humanity itself. Central to this concern is the idea of "intelligence explosion" or "foom," where recursively self-improving AI systems rapidly transition from subhuman general intelligence to superintelligence, potentially outpacing our ability to control or understand them. A misaligned AI might make a series of internally consistent decisions that have catastrophic outcomes (such as optimizing the number of paper clips in the world by turning all matter into paper clips and fighting humans). While this seems farfetched to us, and most people who have ever attempted to design any computational system, several of the underlying concepts such as alignment, bias, and human-AI teaming effects, are very real concerns for the deployment of AI systems in medicine, and worth diving into at length today. This is our opportunity for a pre-mortem: an exercise to imagine darker alternative futures so that we may avoid them.
First, let’s talk about alignment. All actors, whether AI or human, may have different preferences. When actors attempt to cooperate, one of the trickiest parts of the interaction is successfully managing these differing preferences (in economics, this has been studied for decades as the Principal-Agent problem). For example, if I hire a nurse to perform home blood pressure monitoring, I should design the rewards and engagement structures (salary, others) to make it more likely that they will do the work I intended. Similarly, if I ask an AI to write code, I should ensure that it is only “rewarded” (programmatically, with its favorite 10010101’s) when the work is successfully completed. Otherwise, it might output the score from the Dodgers game and call it a day. The doomers worry that solving Principal-Agent problems with superintelligent and highly connected AI may be impossible (since it’s smarter than us), and the pace of AI superintelligence may accelerate (called foom) faster than we can manage. Before we can pull the plug on our AI, we will all be turned into paper clips, or so the theory goes.
What does alignment mean for medical AI systems? Frankly, I’m less afraid of superintelligent foom and doom healthcare AI’s, but far more afraid of misaligned AI. First, defining human preferences is devilishly tricky. Patient satisfaction measures are notoriously fraught: repeated studies show that the most satisfied patients are more likely to die and less likely to receive care in some settings.

Secondly, even if we can define valid preferences for patients, the patients are not going to be creating the AI models that are deployed clinically. Both capital and regulatory structures dictate where these models will be created: large insurers, hospital systems, or even governments. It would be illogical to believe that this historically misaligned sector will do better with AI than it has with communication, financing, or care provision. How do we weigh the desires of an insurer (reduce costs), patients (live longer, usually), hospitals (run a business, serve a community), and governments, in deciding what recommendations we should make? Even “simple” diagnostic algorithms have an alignment challenge: whom should the AI algorithm designers ask about the relative risk of overdiagnosing cancer versus missing a lifesaving opportunity? Or should we aim for the most “accurate” diagnostic, pretending that these scenarios are all equally valuable? Unless we undertake a massive, burdensome and unfinanced effort to tackle our incentives problem, AI can only replicate our existing challenges.
Bias is similarly important, but it may not mean what we are used to thinking about in the DEI-sense of the word. Addressing algorithmic performance across definable categories of persons is difficult, but possible. We should know to look for bias in our data and our policies (although we must be better at this). But there’s no reason to believe that the multidimensional interactions within an AI model will neatly map onto our existing protected classes of persons in a human way. Bias might occur due to characteristics of hospitals, physicians, procedures, subtle geographies, or any number of a myriad of interactions between underexplored, machine-generated, and potentially uninterpretable features (variables). And what do we do with uninterpretable and biased systems? It’s not as simple as some sort of restorative justice effort where we “add-in” a factor to “correct” for race or orientation. Algorithmic bias could be worsened by efforts to “suppress” it using human-interpretable categories.
Bias and alignment also have important interaction terms. When we can’t articulate our preferences, can’t measure our biases, and consistently build systems that have unclear behavioral properties, the final result may be worse than the sum of these challenges. On a more superficial level, we can instruct large language models to be “better” than the observed behavior of physicians: “be empathetic”, “explain at the level of a 7th grader”, “don’t be racist”, etc. But who decides, how those decisions are made, how are decisions represented to stakeholders, and how are they validated? These are difficult questions that we have never shown the ability to grapple with as a society and sector.
For example: An AI chatbot is deployed to interact with patients by an insurer. Maybe it starts as a GoodBot that is found to actually drive up costs (accidentally, since the behaviors of systems are difficult to predict), but then is modified over time to meet the incentives of its creator (minimize costs). You could similarly imagine an EvilCo creating an EvilBot that was instructed to always provide highly satisfying, kind and compassionate results that also reduced the likelihood of patients’ requesting highly expensive tests. Given the opacity of AI systems, and the underlying brokenness of health care, it would be hard to imagine any other path forward.
Where does Medical Education fit into this puzzle? Historically, MedEd is an (almost) unfunded mandate within medicine. Both students and trainee physicians are valued far more for their cheap sources of labor, and educational endeavors are loss-leaders for most MedEd institutions. As we integrate AI systems into medicine, who is going to pay attention to the way that these systems interact with the cognitive process of human learning? Entire realms of competence may be lost if medical professionals opt out of those vital, messy, mistake-prone, and difficult experiences that form our identities.
Is medical AI more like a “spellchecker” or an “autopilot”? How do learners learn “with” AI? When these costly decisions, in the most likely scenario, are made in an opaque and abstracted design phase (by industry) and purchased (by payers and healthcare systems), who is watching the store? How do we center the human-AI interaction on improving the human side of the system, while simultaneously improving the quality of the dyad, as best we can measure?
The learning behaviors of humans in human-AI dyads are under-examined and unstudied. How we meet this challenge will be a critical determinant of the success of the medical enterprise overall and of our adoption of human-AI systems.
In technical and procedural disciplines such as our beloved neurosurgery, we are working to build a short-term future where AI can help teach and explain surgery in a way that improves human health worldwide.
But what about our more cognitively inclined brethren and sister-en? If we can learn to think “better” through interactions with AI, we may dramatically improve human health worldwide. However, if we learn to think “less”, we may never recognize the incredible costs of lost human performance, creativity, and future innovation.
Unlike the doomers and their foom, we can’t pause these developments, nor should we. Our patients demand better - it would be unethical NOT to improve medicine with AI.
These care improvements require clinicians, particularly educators, to get in the driver’s seat.
Who’s coming with us?

Best of Twitter - RIP Elno.
Feeling inspired? Drop us a line and let us know what you liked.
Like all surgeons, we are always looking to get better. Send us your M&M style roastings or favorable Press-Gainey ratings by email at ctrl.alt.operate@gmail.com